Creating a GraphQL Server in Node.js
You've no doubt heard of GraphQL, the graph-based query language from Facebook. Since its release in 2015, increasing numbers of data providers have been offering a GraphQL endpoint. This endpoint is generally offered alongside a traditional REST based API.
I have come to prefer a GraphQL endpoint on the frontend. I like being able to query for the specific data I want, avoiding issues of over- or under-fetching. I like the self-documenting nature of GraphQL, as its type-based schema describes exactly what is expected and is returned. I have wrestled with REST APIs too many times only to realize that the documentation is outdated or wrong.
On the backend, though, I've continued to provide REST endpoints. Traditional HTTP verbs and routing are familiar, and I can get something functional out the door very quickly.
The question I wanted to answer in this article is, what does it take to get a GraphQL API up and running?
Context
To help give this article some context, I created a fictional surf shop. I've been out on my kayak a lot this summer, and that's what this particular shop sells. The code that accompanies this article can be found here.
My surf shop uses a MongoDB database and has a Fastify server ready to go. You can find the starter code for this shop here, along with a seeding script, if you want to follow along. You will need Node and MongoDB installed, which is beyond the scope of this article, but click on the names to go to the installation pages.
To make this a realistic scenario, I want to allow my current clients who are consuming the REST API to be unaffected as I add a GraphQL endpoint.
Let's get started!
GraphQL Schema
There are two libraries we need to add to our project to get up and running with GraphQL. The first is, unsurprisingly, graphql, and the second is mercurius. Mercurius is the Fastify adapter for GraphQL. Let's install them:
yarn add graphql mercurius
GraphQL is schema-based, which means that our API will always be documented and type safe. This is a significant benefit for our consumers and helps us as we think about the relationships between the data.
Our store has two types, the Craft and the Owner. Navigating to the Mongoose models, you can see what fields are available on each. Let's look at the Owner model.
The Mongoose model looks like this:
const ownerSchema = new mongoose.Schema({
firstName: String,
lastName: String,
email: String,
});
We're going to create a schema directory, which is an index.js file, and then create our GraphQL schema. This OwnerType in this schema will look very similar to the Mongoose one.
const OwnerType = `type OwnerType {
id: ID!
firstName: String
lastName: String
email: String
}`;
Template strings are used to define our types, starting with the keyword type and the name of our type. Unlike a JavaScript object, there are no commas after each line of our type definition. Instead, each line features the field name and its type separated by a colon. I've used the ID and String types in my definition. You'll notice that ID is followed with an exclamation point, !, which labels this as a compulsory, non-nullable field. All other fields are optional.
I'm going to add this type to the Query type of my schema now.
const schema = `
type Query {
Owners: [OwnerType]
Owner(id: ID!): OwnerType
}
${OwnerType}
`;
You'll see that Owners is typed as returning an array of the OwnerType, indicated by the square brackets.
Owner requires the querying consumer to pass an id field. This is denoted by the value in parentheses, (id: ID!), showing both the name of the field and the type to which it must confirm.
Lastly, we'll export this schema from this file and import it into our main index.js file.
module.exports = { schema };
and
const { schema } = require("./schema");
While we are importing the schema, we can import the mercurius plugin and register it with Fastify.
const mercurius = require("mercurius");
fastify.register(mercurius, {
schema,
graphiql: true,
});
In the options plugin, we will pass the schema and one other property - we'll set graphiql equal to true.
GraphiQL
GraphiQL is a browser-based interface designed to explore and work with your GraphQL endpoint. Now that it is set equal to true, we can run our server and navigate to http://localhost:3000/graphiql to find this page.
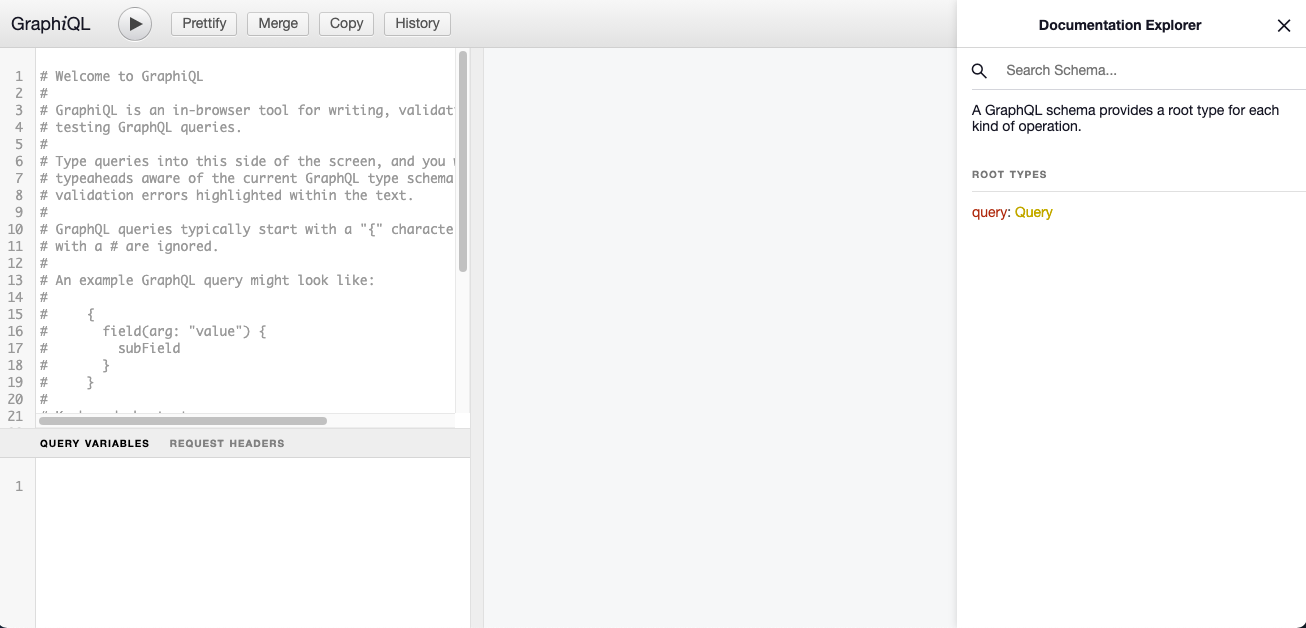
With this tool, we can do the following:
- Write and validate our queries.
- Add query variables and request headers to help with testing.
- Get the results back from our API.
- Explore the documentation generated by our schema.
Exploring the schema now shows a root type of query: Query. It was to this type that we added our Owner and Owners. Clicking on this shows the following:
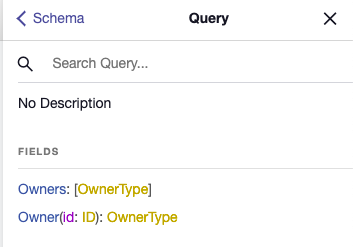
and clicking on either of them shows the corresponding type:
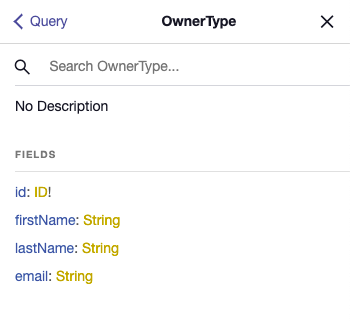
I'm going to go ahead and set-up the rest of the type definitions. You can check the source code to see how I've added the Craft type and added a crafts field to the Owner type.
Once I've done that, my Query type now looks like this:
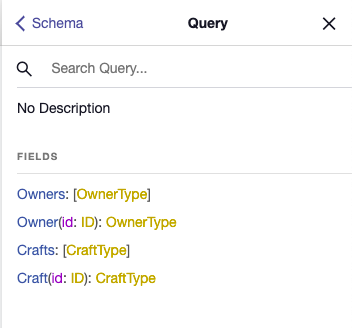
The field relationships have all been set up, but we are unable to get any data from them yet. To do that, we'll need to explore two concepts: queries and resolvers.
GraphQL Queries
At its heart, GraphQL is a query language; it's even in the name! But, so far, we haven't executed any queries. The GraphiQL tool has autocomplete, so we can start constructing our queries now. The following query should return the name of all the Crafts.
query {
Crafts {
name
}
}
When we execute, though, we get a null response.
{
"data": {
"Crafts": null
}
}
That's because we haven't set up any resolvers. A resolver is a function that GraphQL runs to find the data it needs to resolve a query.
For this project, I am going to define the resolvers in the schema/index.js file, alongside the schema. I already have controllers for both of the data types used by my REST API routes. I'm going to use these controllers, with some adaptation, to serve my GraphQL endpoint.
First, I'll import the controllers:
const craftController = require("../controllers/craftController");
const ownerController = require("../controllers/ownerController");
Then, I'll create a resolvers object:
const resolvers = {}
This object should have a key for each root type for which we want to provide resolvers. For our use, we have a single root type, namely Query. The value for this key should be a function executed to get the required data. This is how it would look for our Crafts field:
const resolvers = {
Query: {
async Crafts() {
return await craftController.getCrafts();
},
},
};
We then export the resolvers function, import it into our main index.js, and pass it to our plugin options object, along with the schema.
// in /src/schema/index.js
module.exports = { schema, resolvers };
// in /src/index.js
const { schema, resolvers } = require("./schema");
fastify.register(mercurius, {
schema,
resolvers,
graphiql: true,
});
Now, when we run the previous query, we should get all the names of the crafts in our database.

Awesome! However, what if we want to query for a specific craft? This requires a little more work. First, let's construct the query in our GraphiQL editor.
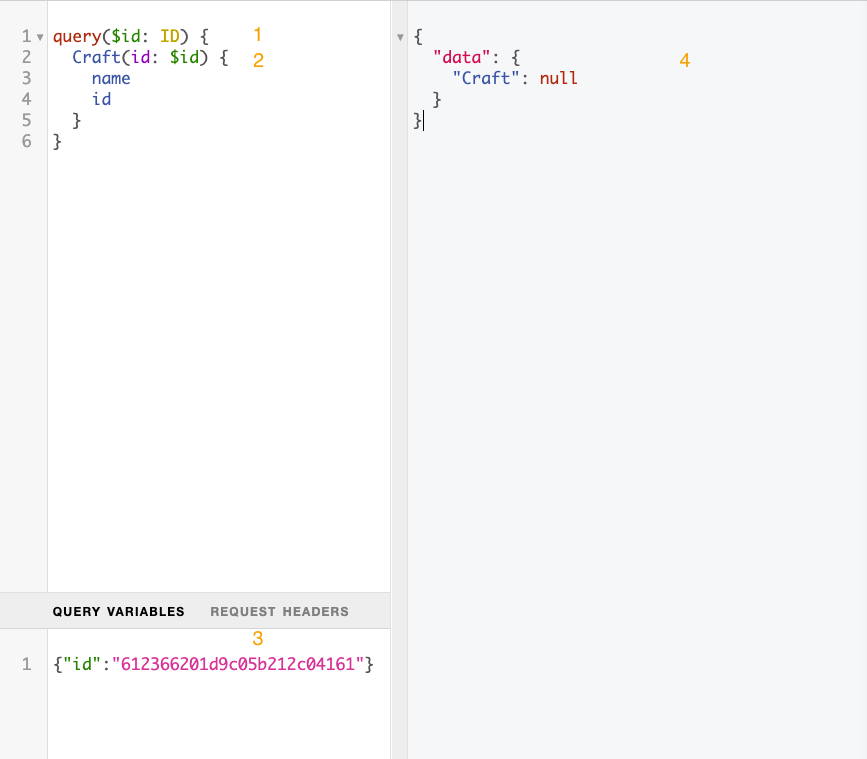
The query setup looks very similar, with a few differences:
- I need to pass in a query variable. After the keyword
query, we indicate the name and type of the variable that is going to be passed. The variable should begin with a dollar sign ($). - Here, I am using the variable
$idas the value for the field to query on my Craft field. - The value of the query variable is being passed as JSON.
- Lastly, I get my response back.
At the moment, I don't have any data returned. Let's fix that!
Back in my resolvers, I'll add a function for Craft. The first positional argument is the parent, which I don't need for this operation, so I'll use an underscore there. The second is the arguments passed into the query from which I want to decompose the id:
const resolvers = {
Query: {
async Crafts() {
return await craftController.getCrafts();
},
async Craft(_, { id }) {
return await craftController.getCraftById({id})
},
},
};
Currently, my getCraftById function is expecting the request object. I'll need to update the function in src/controllers/craftController.js.
This original function
// Get craft by id
exports.getCraftById = async (request, reply) => {
try {
const craft = await Craft.findById(request.params.id);
return craft;
} catch (error) {
throw boom.boomify(error);
}
};
becomes
exports.getCraftById = async (request, reply) => {
try {
const id = request.params === undefined ? request.id : request.params.id;
const craft = await Craft.findById(id);
return craft;
} catch (error) {
throw boom.boomify(error);
}
};
Awesome! Now, when we execute our query, a result will be returned.
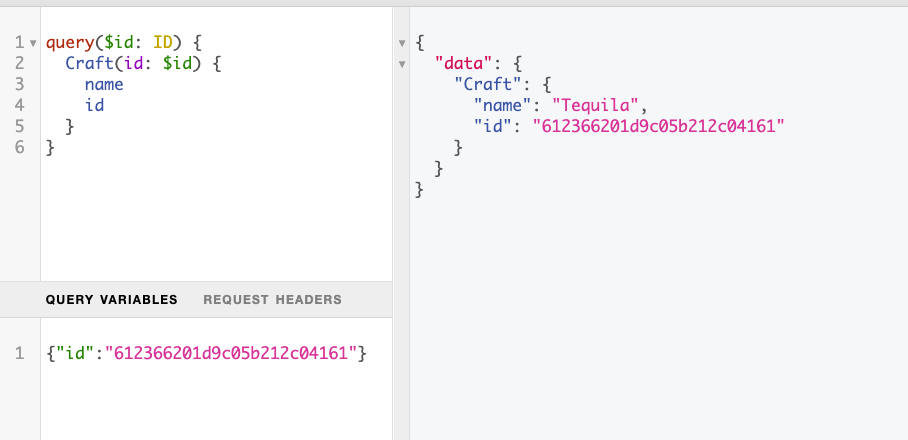
We'll need to help GraphQL to fill the fields that link to other types. If our consumer queried for the current owner of the craft, it would come back as null. We can add some logic to get the owner based on the owner_id, which is stored in the database. This can then be appended to our craft object before being passed back to our user.
async Craft(_, { id }) {
const craft = await craftController.getCraftById({ id });
if (craft && craft.owner_id) {
const owner = await ownerController.getOwnerById({
id: craft.owner_id,
});
craft.owner = owner;
}
return craft;
},
Our ownerController.getOwnerById will need to be updated in the same way as the corresponding craft function. But, once that is handled, we can query the owner freely.
You can check the finished-code directory to find the resolvers for all the other fields and the updated controller functions.
GraphQL Mutations
I can now provide for queries to a GraphQL endpoint confidently; all the read operations are some adaptations of what we have done already. What about other operations? Specifically, what about Create, Update, and Delete?
In GraphQL, each of these operations is referred to as a mutation. We are changing the data in some way. Setting up the backend for a mutation is almost exactly the same as setting up a query. We need to define the mutation in the schema and then provide the resolver function that will be executed when the mutation is called.
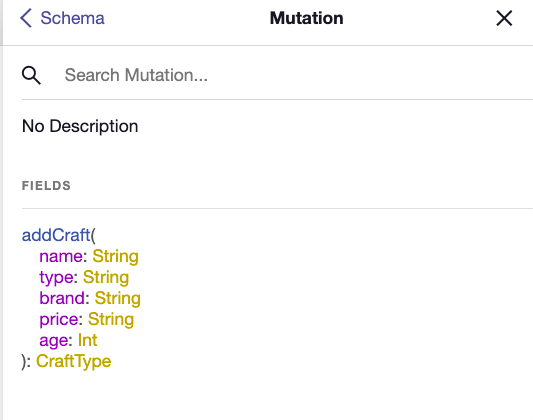
So, in /schema/index.js, I'm going to extend the Mutation type and add an addCraft mutation.
type Mutation {
addCraft(
name: String
type: String
brand: String
price: String
age: Int
): CraftType
}
As with previous field definitions, the values in parentheses show what fields can be passed into the function. This are each passed alongside their types. We then follow with what the mutation will return. In this case, an object in the shape of our CraftType.
Checking this out in GraphiQL, we can see that mutation is now a root type, when we click through, that our addCraft mutation exists in the schema.
Constructing a mutation in GraphiQL looks identical to constructing a query. We'll need to pass in query variables as we did before, and it'll look something like this:
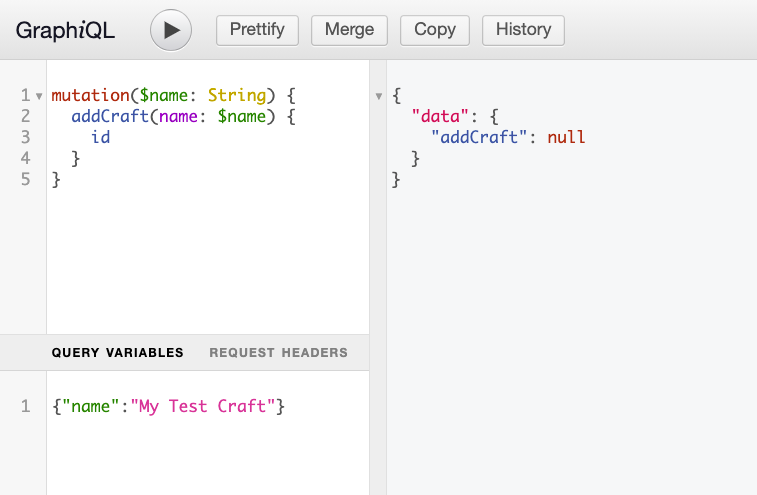
When we execute, though, we get a null response. This is hopefully unsurprising because we haven't yet created a resolver for this mutation. Let's do that now!
We'll add a Mutation key to our resolvers object and a function for our addCraft mutation.
Mutation: {
async addCraft(_, fields) {
const { _id: id } = await craftController.addCraft({ ...fields });
const craft = { id, ...fields };
return craft;
},
},
Our current addCraft function only returns the Mongoose response, which is the _id field. We'll extract that and return the entered fields, allowing us to conform to the CraftType we declared earlier.
The update and destroy functions are identical in their configuration and setup. In each case, we're extending the Mutation type in the schema and adding a corresponding resolver.
You can check the finished-code directory to find the resolvers for some of the other mutations.
Conclusion
I entered into this wondering if building a GraphQL server was a huge unnecessary hassle. I finish quietly confident that I'll use GraphQL for my next backend project.
There is initially a bit more setup and boilerplate than reaching straight out for Mongo through our REST API. This could potentially be a sticking point. However, I think there are some compelling points that make this worthwhile.
No longer do you need to provide an endpoint for some niche use of your application. The consumer only needs to call on the fields that they need for a given context. This saves a cluttered routes file and multiple calls to your API when one will do.
In updating the schema and resolvers, you make this data immediately available to your consumers. While you can mark fields as deprecated, you could leave legacy fields in place with little cost to the user. Furthermore, this is a self-documenting API. Never again will your documentation site fall out of sync with the current state of your API.
Are you convinced? Will you move over to GraphQL, or are you on team REST API forever?

Written by
Kevin Cunningham
Kevin Cunningham is the founder of doing&learning, working with individuals and teams to level up their development skills. As a lifetime educator, Kevin loves to create, deliver and engage in learning experiences and does this regularly by teaching online and in-person. As a learning loving developer, Kevin loves taking on new challenges to push his understanding and help his clients achieve their best results. Away from the keyboard, you'll find Kevin walking and kayaking with his wife and kids.