Developing software can be challenging, but maintaining it is far more challenging. Maintenance includes software patches and server maintenance. In this post, we will focus on server management and maintenance.
Traditionally, servers were on-premises, which means buying and maintaining physical hardware. With cloud computing, these servers no longer need to be owned physically. In 2006, when Amazon started AWS and introduced its EC2 service, the era of modern cloud computing began. With this type of service, we no longer needed to maintain physical servers or upgrade physical hardware. This solved a lot of problems, but server maintenance and resource management are still up to us. Taking these developments to the next level, we now have serverless technology.
What Is Serverless Technology?
Serverless technology helps offload the work of managing and provisioning servers to a cloud provider. In this post, we will be discussing AWS.
The term serverless does not mean that there is no server at all. There is a server, but it is fully managed by the cloud provider. In a sense, for the users of serverless technology, there is no visible server. The servers are not directly visible to us, and the job of managing them is automated by the cloud provider. Here are some of the characteristics that make it serverless:
- No operational management - No need for patching servers or managing them for high availability;
- Scale as needed - From serving only a few users to serving millions of users;
- Pay as you go - The cost is managed based on usage.
Serverless technology can be categorized as follows:
- Compute (e.g., Lambda and Fargate)
- Storage (e.g., S3)
- Data Store (e.g., DynamoDB and Aurora)
- Integration (e.g., API Gateway, SNS, and SQS)
- Analytics (e.g., Kinesis and Athena)
Why Use Serverless Technology?
Cost
Pay as you go is one of the main advantages of using serverless technology. When there is an unpredictable change in traffic volume, you need to scale the server up or down based on usage patterns, but scaling with self-managed autoscaling can be difficult and inefficient. Serverless computing, such as AWS Lambda, can easily help save costs because there is no need to pay during idle times.
Developer Productivity
Since serverless computing refers to fully managed services provided by a cloud provider, there is no need for developers to provision servers or develop server applications. Developers can start coding right away without needing to manage the server. This approach also removes the need for patching servers or managing autoscaling. Saving all of this time helps increase developers' productivity.
Elasticity
Serverless computing is highly elastic and can scale up or down based on usage. A spike in users can be handled easily. This can be a major advantage and helps save a lot of time for developers.
High Availability
When computing is serverless and managed by a cloud provider and servers have high uptime, failovers are handled automatically. Managing these kinds of issues requires specialized skills. With the serverless approach, the ops' and developers' work can be done by a single person.
How To Implement Serverless Functionality In Ruby
According to AWS, Ruby is one of the most widely used languages in AWS. Lambda started supporting Ruby in November 2018. We will be building a web API in Ruby using only the serverless technologies provided by AWS.
To create a serverless infra in AWS, we can simply log in to the AWS console and start creating them. However, we want to develop something that is easily testable and facilitates disaster recovery. We will write the serverless feature as a code. To do so, AWS provides the serverless application model (SAM). SAM is a framework used to build serverless applications in AWS. It provides YAML-based syntax for designing Lambda, databases, and APIs. AWS SAM applications can be built using AWS SAM-CLI, which can be downloaded via this link.
AWS SAM CLI is built on top of AWS Cloudformation. If you are familiar with writing IaC with CoudFormation, this will be very simple. Alternatively, you can also use the serverless framework. In this post, I will be using AWS SAM.
Before using SAM CLI, make sure you have the following:
We will be developing a serverless application. We will begin by creating a few serverless infra, such as DynamoDB and Lambda, in our application. Let us start with the database:
DynamoDB
DynamoDB is a serverless AWS-managed database service. As it is serverless, it is very quick and easy to setup. To create DynamoDB, we define the SAM template as follows:
AWSTemplateFormatVersion: '2010-09-09'
Transform: AWS::Serverless-2016-10-31
Resources:
UsersTable:
Type: AWS::Serverless::SimpleTable
Properties:
PrimaryKey:
Name: id
Type: String
TableName: users
With SAM CLI and the above template, we can create a basic DynamoDB table.
First, we need to build a package for our serverless app. For this, we run the following command. This will build the package and push it to s3. Make sure you have created the s3 bucket with the name serverless-users-bucket before running the command:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
The s3 now becomes the source for the template and the code for our serverless app, which we will talk about while we create a Lambda function for it.
We can now deploy this template to create the DynamoDB:
$ sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
With this, we have the DynamoDB setup in place. Next, we will create a Lambda, where this table will be used.
Lambda
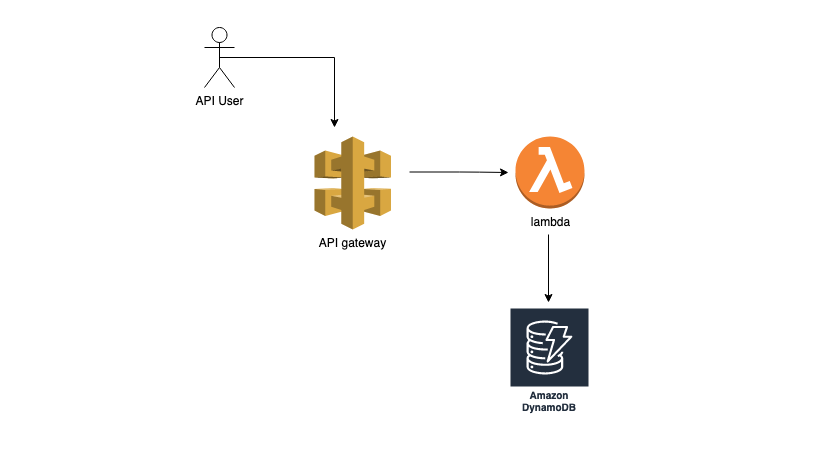
Lambda is a serverless computing service provided by AWS. It can be used to execute code on an as-needed basis without requiring actual server management, where the code gets executed. Lambda can be used to run Async processes, REST APIs, or any scheduled jobs. All we need to do is write a handler function and push the function to AWS Lambda. Lambda will do the job of executing the task based on events. An event can be triggered by various sources, such as the API gateway, SQS, or S3; it can also be triggered by another codebase. When triggered, this Lambda function receives events and context parameters. The values in these parameters differ based on the source of the trigger. We can also manually or programmatically trigger the Lambda function by passing these events to the handler. A handler takes two arguments:
Event - Events are usually a key-value hash passed from the source of the trigger. These values are automatically passed when they are triggered by various sources, such as SQS, Kinesis, or an API gateway. When triggering manually, we can pass the events here. The event contains input data for the Lambda function handler. For example, in an API gateway, the request body is contained inside this event.
Context - Context is the second argument in the handler function. This contains specific details, including the source of the trigger, Lambda function name, version, request-id, and more.
The output of the handler is passed back to the service that triggered the Lambda function. The output of a Lambda function is the return value of the handler function.
AWS Lambda supports seven different languages in which you can code, including Ruby. Here, we will be using AWS Ruby-sdk to connect to DynamoDB.
Before writing the code, let us create an infra for Lambda using a SAM template:
AWSTemplateFormatVersion: "2010-09-09"
Transform: AWS::Serverless-2016-10-31
Description: "Serverless users app"
Resources:
CreateUserFunction:
Type: AWS::Serverless::Function
Properties:
Handler: users.create
Runtime: ruby2.7
Policies:
- DynamoDBWritePolicy:
TableName: !Ref UsersTable
Environment:
Variables:
USERS_TABLE: !Ref UsersTable
In the handler, we write the reference to the function to be executed as Handler: <filename>.<method_name>.
Refer to the serverless policy template for a policy that you can attach to the Lambda based on the resource it uses. Since our Lambda function writes to DynamoDB, we have used DynamoDBWritePolicy in the policies section.
We are also providing the env variable USERS_TABLE to the Lambda function so that it can send requests to the specified database.
So, that is what we need for the Lambda infra. Now, let us write the code to create a user in DynamoDB, which the Lambda function will execute.
Add the AWS record to the Gemfile:
# Gemfile
source 'https://rubygems.org' do
gem 'aws-record', '~> 2'
end
Add code to write the input to DynamoDB:
# users.rb
require 'aws-record'
class UsersTable
include Aws::Record
set_table_name ENV['USERS_TABLE']
string_attr :id, hash_key: true
string_attr :body
end
def create(event:,context:)
body = event["body"]
id = SecureRandom.uuid
user = UsersTable.new(id: id, body: body)
user.save!
user.to_h
end
It is very quick and easy. AWS provides the aws-record gem for accessing DynamoDB, which is very similar to Rails' activerecord.
Next, run the following commands to install the dependencies.
Note: Make sure that you have the same version of Ruby as defined in the Lambda. For the example here, you need Ruby2.7 installed on your machine.
# install dependencies
$ bundle install
$ bundle install --deployment
Package the changes:
$ sam package --template-file sam.yaml \
--output-template-file out.yaml \
--s3-bucket serverless-users-bucket
Deploy:
sam deploy --template-file out.yaml \
--stack-name serverless-users-app \
--capabilities CAPABILITY_IAM
With this code, we now have the Lambda running, which can write the input to the database. We can add an API gateway in front of the Lambda so that we can access it via HTTP calls. An API gateway provides a lot of API management functionalities, such as rate limiting and authentication. However, it can become expensive based on usage. There is a cheaper option of using only an HTTP API without API management. Based on the use case, you can choose the most appropriate one.
AWS Lambda has a few limits. Some of them can be modified, but others are fixed:
- Memory - By default, a Lambda has 128 MB memory during its execution time. This can be increased up to 3,008 MB in increments of 64 MB.
- Timeout - The Lambda function has a time limit for executing the code. The default limit is 3 seconds. This can be increased up to 900 seconds.
- Storage - Lambda provides a
/tmpdirectory for storage. The limit of this storage is 512 MB. - Request and Response size - Up to 6 MB for a synchronous trigger and 256 MB for an asynchronous trigger.
- Environment variable - Up to 4KB
Since Lambda has some of these limits, it is better to write code that fits within these limitations. In case they don't, we can split the code so that one Lambda triggers another. There is also a step function provided by AWS, which can be used to sequence multiple Lambda functions.
How Can We Test Serverless Applications Locally?
For serverless applications, we need to have a vendor that provides managed serverless services. We are dependent on AWS to test our application. To test the application, there are a few local options provided by AWS. Some open-source tools that are compatible with AWS serverless technologies can also be used to test the application locally.
Let us test our Lambda function and DynamoDB. To do so, we need to run these locally.
First, create a docker network. The network will help communicate between the Lambda function and DynamoDB.
$ docker network create lambda-local --docker-network lambda-local
DynamoDB local is a local version of DynamoDB provided by AWS, which we can use to test it locally. Run DynamoDB local by running the following docker image:
$ docker run -p 8000:8000 --network lambda-local --name dynamodb amazon/dynamodb-local
Add the following line in the user.rb file. This will connect the Lambda to the local DynamoDB:
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://dynamodb:8000'
)
UsersTable.configure_client(client: local_client)
Add an input.json file, which contains the input for the Lambda:
{
"name": "Milap Neupane",
"location": "Global"
}
Before executing the Lambda, we need to add the table to the local DynamoDB. To do so, we will be using the migration functionality provided by aws-migrate. Let us create a file migrate.rb and add the following migration:
require 'aws-record'
require './users.rb'
local_client = Aws::DynamoDB::Client.new(
region: "local",
endpoint: 'http://localhost:8000'
)
migration = Aws::Record::TableMigration.new(UsersTable, client: local_client)
migration.create!(
provisioned_throughput: {
read_capacity_units: 5,
write_capacity_units: 5
}
)
migration.wait_until_available
Finally, execute the Lambda locally using the following command:
$ sam local invoke "CreateUserFunction" -t sam.yaml \
-e input.json \
--docker-network lambda-local
This will create the user's data in the DynamoDB table.
There are options, such as localstack, for running AWS stacks locally.
When Should Serverless Computing Be Used
When deciding whether to use serverless computing, we need to be aware of both its benefits and shortcomings. Based on the following characteristics, we can decide when to use the serverless approach:
Cost
- When the application has idle time and inconsistent traffic, Lambdas are good because they help reduce costs.
- When the application has a consistent traffic volume, using AWS Lambda can be costly.
Performance
- If the application is not performance-sensitive, using AWS Lambda is a good choice.
- Lambdas have a cold boot time, which can cause slow response times during a cold boot.
Background processing
- Lambda is a good choice to use for background processing. Some open-source tools, such as Sidekiq, have server scaling and maintenance overhead. We can combine AWS Lambda and AWS SQS queue to process background jobs without the hassle of server maintenance.
Concurrent processing
- As we know, concurrency in Ruby is not something we can do easily. With Lambda, we can achieve concurrency without the need for programming language support. Lambda can be executed concurrently and helps improve performance.
Running Periodic or one-time scripts
- We use cron jobs to execute Ruby codes, but server maintenance for cron jobs can be difficult for large-scale applications. Using event-based Lambdas helps in scaling applications.
These are some use cases for Lambda functions in serverless applications. We do not have to build everything serverless; we can build a hybrid model for the above-specified use cases. This helps in scaling applications and increases developers' productivity. Serverless technologies are evolving and getting better. There are other serverless technologies, such as AWS Fatgate and Google CloudRun, which do not have the limitations of AWS Lambda.


