Building Autocomplete With DynamoDB and Lambda
We recently released a new search key autocomplete feature here at Honeybadger. It was such a fun project that I just had to write it up for you all. Not only does it showcase an exciting use of DynamoDB, but it also shows the challenges of using DynamoDB cost-effectively with large amounts of frequently-updated data.
What do we mean by search key autocomplete?
Honeybadger stores error reports. Those reports contain lots of data (like params, session, context) that is searchable.
Need to find all errors caused by "Bob"? Just do this search:
context.user.first_name:"Bob"
As you can imagine, nested searches are handy. However, they have had two big problems. To do the above search we had to
- Remember that
context.user.first_nameis a valid key - Type
context.user.first_namein manually, without any typos
For the longest time, we've wanted to add a way to autocomplete these keys. We finally made it happen. Here's the result:
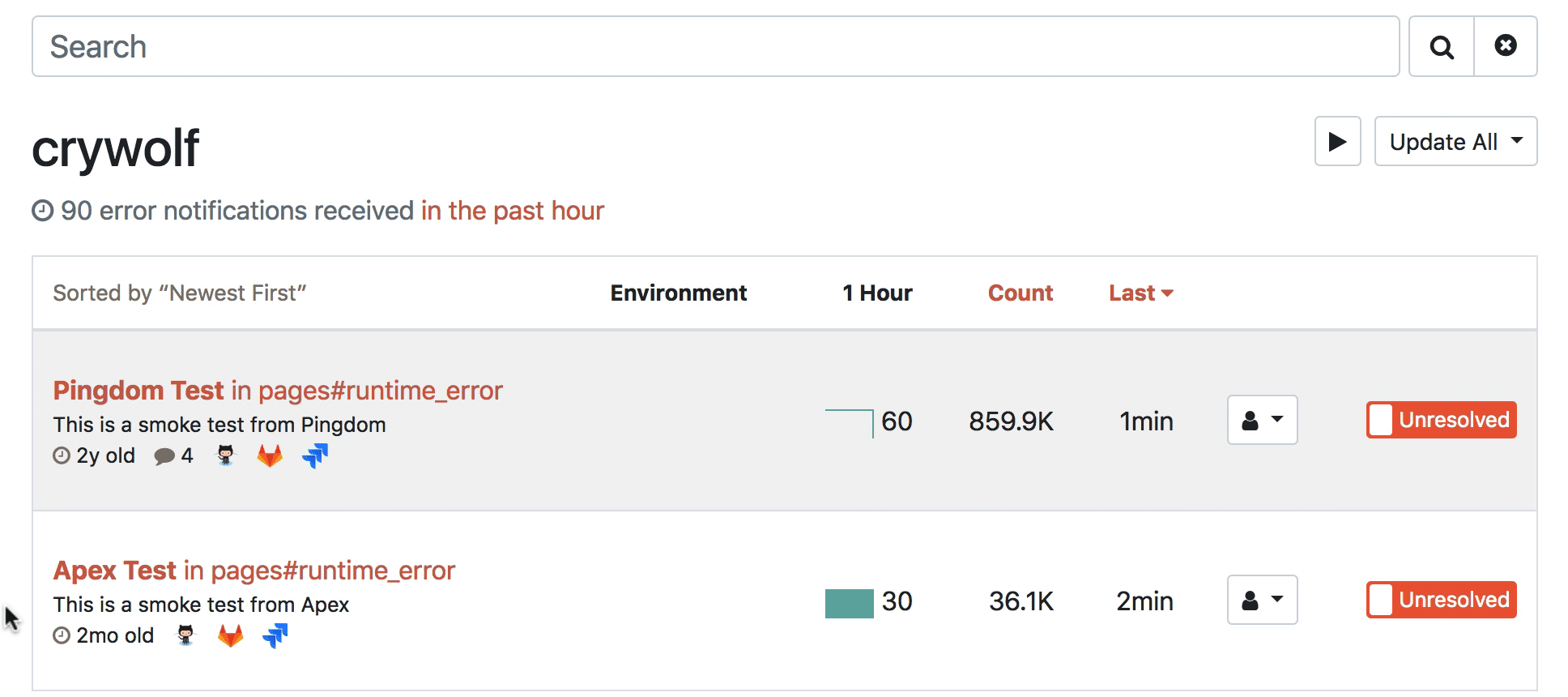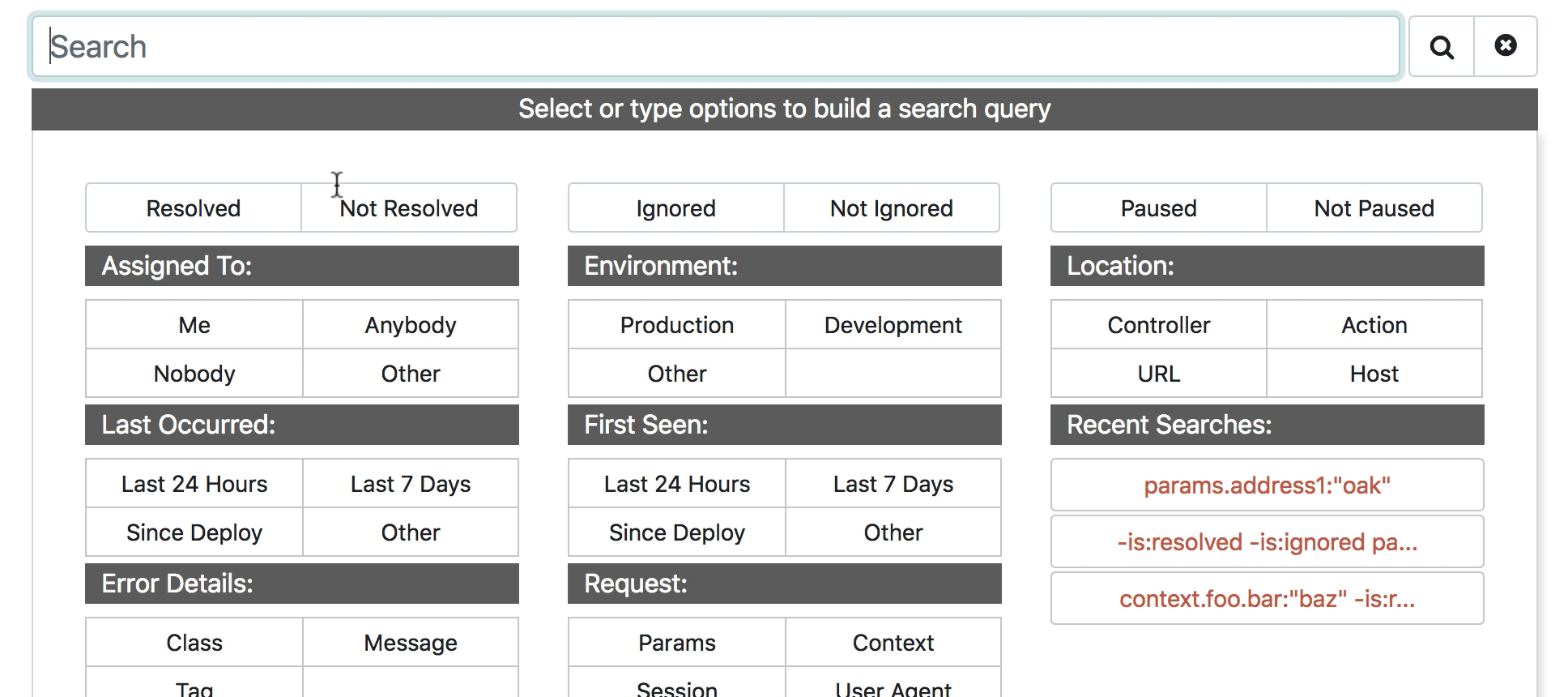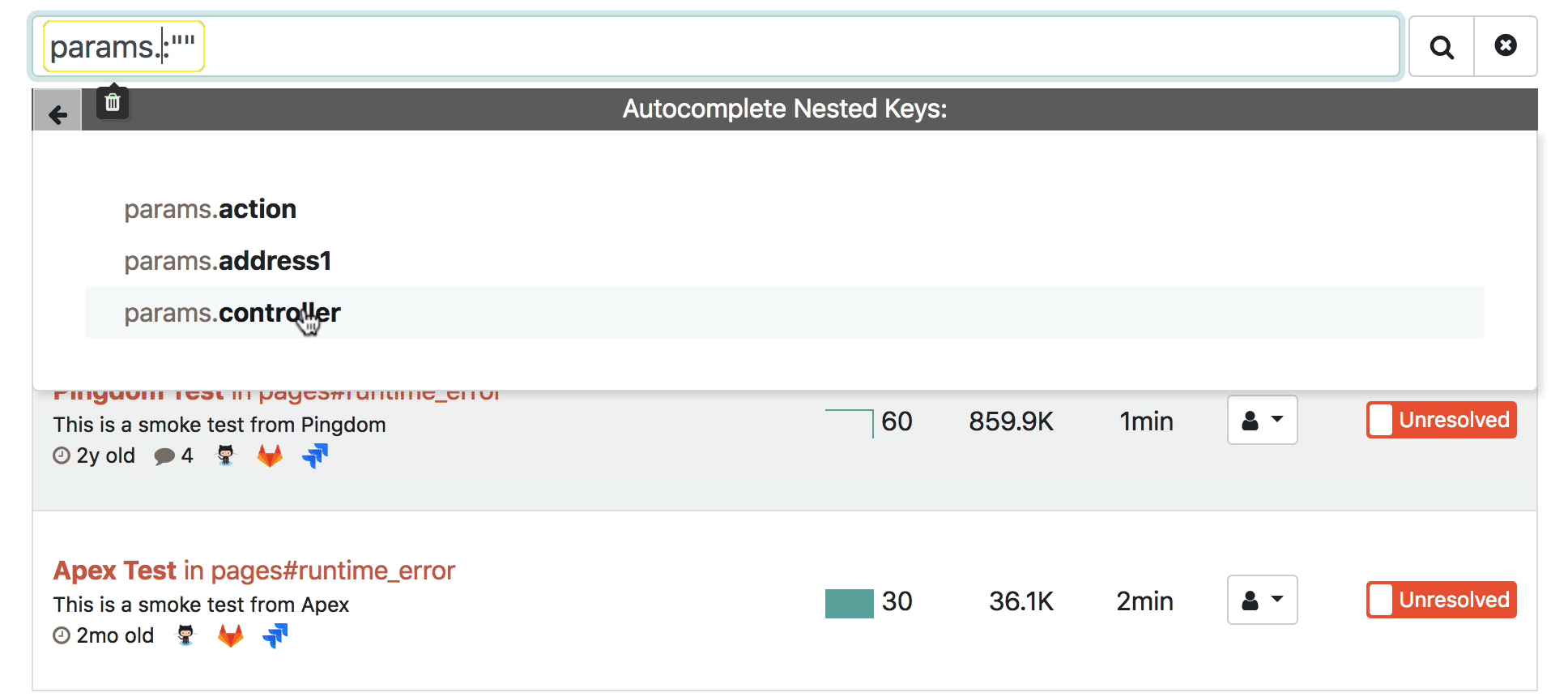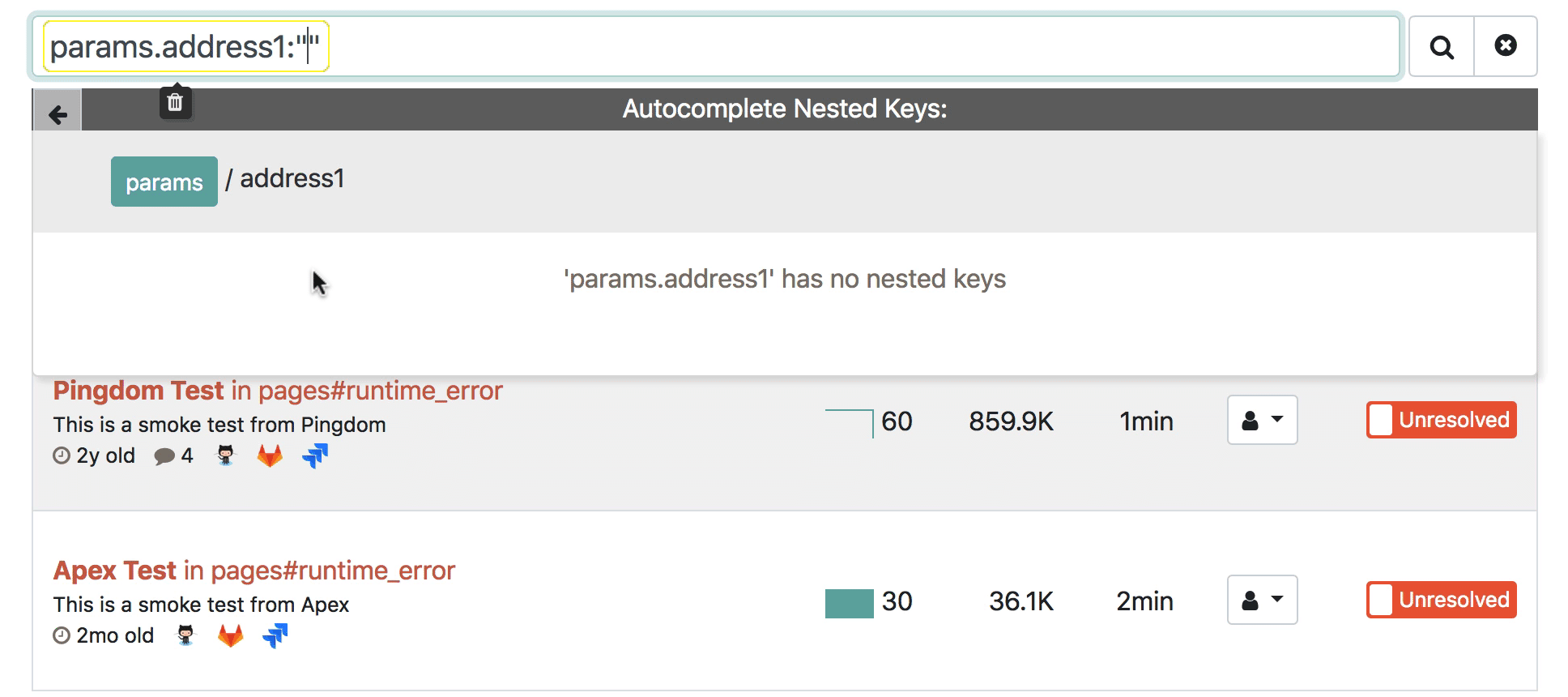
The 10,000ft view
Many key names are deeply nested. An example is params.user.name.first.
We wanted our UI to let the user autocomplete one segment at a time. This approach is very similar to how you can autocomplete directory names in bash.
Here are some example autocompletions:
params.u => params.user
params.user.n => params.user.name
params.user.name.fi => params.user.name.first
The natural solution for us was to build a web service that could provide these autocompletions. Once we had that, it would be relatively simple to hook it up to our existing search UI.
Inputs and outputs
Let's take a look at how we expect our web service to behave given a simplified data set. And by simplified, I mean a single record:
{
parms: {
user: {
name: {
first: "Joe",
last: "User"
},
age: 32
},
controller: "registrations"
}
}
Given any key ( such as "name"), we want to get a list of its child keys (like ["first", "last"]). The table below lists all valid queries for the record above:
| Query | Desired return value |
|---|---|
| params | ['user', 'controller'] |
| params.user | ['name', 'age'] |
| params.user.name | ['first', 'last'] |
| params.user.name.first | [] |
| params.user.age | [] |
| params.controller | [] |
Now we're getting somewhere! All we have to do is build a system that will parse our records and produce the results described.
Requirements
Honeybadger is unique — we process tons of inbound data, but we're a tiny company. So we have a few requirements:
- Reads and writes to the index should occur in constant time, to avoid scaling problems.
- The service must automatically scale to handle load spikes because we have lots of those.
- Hosting cost should be less than $200/mo. Does it look like we're made of money?
- Ongoing ops and maintenance burden should be very low.
- Purging old records should be easy because we expire records in our main DB.
Given all of these requirements, we decided to take a serious look at DynamoDB and Lambda.
Choosing Dynamo
DynamoDB is a key-value store. You can store one or more values for a key, and then look them up later. Pretty simple, right?
In addition to string keys, DynamoDB supports "composite" keys, which have two parts:
- Partition Key - Used to perform a simple key-value lookup.
- Sort Key - Determines the sort order of the returned values.
Critically for us, DynamoDB lets you do queries that:
- Find all records matching the partition key
- ...and extract only the records where the sort key matches a given prefix.
If we have a record in dynamo that looks like this:
partition_key: "params"
sort_key: "user"
When the user types in params.u, All you have to do is ask dynamo for all records where partition_key equals "params" AND sort_key starts_with "u".
That's autocomplete, baby!
Creating the index
We know how we want our autocomplete service to behave. But how does that translate into Dynamo? Imagine that we have the following error data:
{
params: {
user: {
name: {
first: "Joe",
last: "User"
}
}
}
}
Remember how we said we want users to be able to autocomplete each segment of the path separately?
When typing params.user.name.first , the user will be able to autocomplete
params.userparams.user.nameparams.user.name.first
So, instead of creating a record in DynamoDB for every attribute in our data structure, we end up creating a record for every node. Here's what that looks like:
| Partition Key | Sort Key |
|---|---|
| params | user |
| params.user | name |
| params.user.name | first |
| params.user.name | last |
Now when a user types some text like params.user.name.fi, we can autocomplete it by querying dynamo for records where partition_key equals "params.user.name" AND sort_key starts_with "fi".
Implementing the Indexer
We know what our input data looks like. We've designed an index to let us run our queries. Now it's just a matter of populating the index. Let's build a proof of concept and see how it scales.
Here's a simple diagram of how the system should behave:

- After Honeybadger processes an error report, it adds it to a file with 99 others and uploads the file to S3. We didn't have to build this. It was already in place.
- We will create a Lambda function that runs whenever one of these payload files is uploaded. Our function will use the payloads to populate the search index in Dynamo.
To keep things simple, I'm going to show you the business logic of our Lambda function:
# Iterate over a list of error payloads
payloads.each do |payload|
# Iterate over each key in the payload. i.e. `params.user.id`
keys(payload).each do |key|
# Convert nested keys into their multi-row dynamo representations
# `params.user.id` becomes `[["params", "user"], ["params.user", "id"]]`
expand_key(key) do |partition, sort|
# Write each row to dynamo
write_key(partition, sort)
end
end
end
Easy peasy, right? We take our payload, pull the keys out of it, convert them to dynamo rows and store the rows.
If only life were that simple.
It's all about the money, honey
Our proof of concept works. It's even scaleable with AWS's magic scaling sauce. However, it blows our budget in a major way.
At Honeybadger we deal with thousands of error reports per minute, and each report can result in hundreds of writes to our dynamo index. The thing about DynamoDB writes is that they're expensive.
Also, our single-threaded approach to writes means that our Lambda function is slow. We can compensate by running more copies of it, but that costs money.
If we used our naive implementation, we'd be paying $500-$1000 per month instead of our $200 budget, or — spoiler — the $50/mo we actually pay.
To fix this, we need to focus on two things:
- Reducing writes
- Eliminating round-trips between Lambda and DynamoDB.
There is a third item — making dynamo calls asynchronous — which we won't cover here because it's a mechanical implementation detail.
Converting writes to reads
Imagine that someone sends us a spike of 10,000 error reports. Each report may contain different data, but the key names are most likely going to be very similar.
Most of the writes that our naive implementation does are unnecessary because the data is already in Dynamo.
Since reads are around one-fifth the cost of writes, we can cut our bill dramatically if we check for the existence of a record in DynamoDB before doing the write.
# Only write keys that aren't already in dynamo.
# This is about 20% the cost of always writing.
keys.each do |key|
write_to_dynamo(key) unless exists_in_dynamo?(key)
end
Ok, there's a catch. This approach hoses Dynamo's time-based record expiration. Typically, when you update a record, you also update its expiration timestamp. Since we never update after creation, the record can expire too soon.
The workaround that we settled on was to only expire records on Mondays. That way we only have to update the timestamp once per week.
Deduplication
We process error payloads in groups of 100. Our naive implementation iterates over each payload, saving its keys in turn.
This approach is simple but inefficient. If I just indexed the key params.user.name, there's no reason for me to index it again in this batch of 100.
A more efficient approach is outlined below:
# Extract keys from all 100 payloads
keys = extract_keys(payloads)
# Convert all keys to rows
rows = convert_to_rows(keys)
# Dedupe the rows and save
write_to_dynamo(rows.uniq)
Batching DynamoDB Reads and Writes
We can reduce the number of roundtrips between Lambda and DynamoDB by using DynamoDB's batch operations.
The AWS API lets you read up to 100 records at a time, and write up to 25 records. Instead of making 100s of dynamo API requests per invocation, our code usually makes fewer than ten — and those are concurrent.
# This is pseudocode. In real life the dynamo SDK is. a bit more complex
# and you'd want to make these requests concurrently
keys_to_write = deduped_keys.in_groups_of(100).flat_map do |key_group|
key_group - Dynamo.batch_get(key_group)
end
keys_to_write.in_groups_of(25) do |key_group|
Dynamo.batch_put(key_group)
end
Victory!
The system has been up and running for several months. Despite processing tens of thousands of keys per minute, it costs us something like $50/mo to run. The total database size for all of our customers is under 50 MB.
Overall, I'm delighted with how this project turned out, and I'm looking forward to doing more serverless projects.

Written by
Starr HorneStarr Horne is a Rubyist and former Chief JavaScripter at Honeybadger. When she's not fixing bugs, she enjoys making furniture with traditional hand-tools, reading history and brewing beer in her garage in Seattle.