Understanding and Implementing Bubble Sort in Ruby
If you're a software engineer, I would bet that you spend a large portion of your time manipulating data. I personally spend quite a bit of time looking for a particular element. This often requires sorting and searching. Luckily, many of the popular programming languages, Ruby included, have methods to accomplish this built-in, so you don't really have to think about or know what's happening under the hood.
However, understanding the various searching and sorting algorithms is not an inconsequential endeavor. Performance matters, and showing a potential employer or your current manager that you understand the trade-offs of different sorting implementations might just tip the scale during your interview or the promotion you've been vying for.
Bubble Sort: Rabbits and Turtles
One of the first sorting algorithms often taught to computer science students is the bubble sort. It is so popular that even Barack Obama referenced it in this interview.
Let's dive in. Suppose we have an array with the following numbers:
[11,5,7,6,15]
First pass
We will start with the first number in the array, which is 11 in this case, and compare it with the second number in the array, which is 5. Since 11 > 5, we will swap the numbers.
[5,11,7,6,15]
Next, let's compare the 11 with the next element, which is 7. Since 11 > 7, we will swap again.
[5,7,11,6,15]
Now we compare 11 with 6. Since 11 > 6, we will swap again.
[5,7,6,11,15]
Finally, comparing 11 with 15, we will not swap since 11 < 15.
Cool! We have completed the first pass through -- taking the first element (11) and comparing it to all of the other elements in the array.
Second pass
Remember, our array now looks like this:
[5,7,6,11,15]
Let's compare the first two numbers. Since 5 < 7, we do nothing. However, when comparing 7 and 6, we swap since 7 > 6.
[5,6,7,11,15]
Since 7 < 11 and 11 < 15, we complete this pass. As you can see, our array is actually already sorted. However, the algorithm does not know if it is completed because it needs to be able to complete one whole pass without any swaps to know it is sorted.
Third pass
Our algorithm will perform the following comparisons.
5 < 6? Yep.
6 < 7? Yep.
7 < 11? Yep.
11 < 15? Yep.
Bingo! We are sorted!
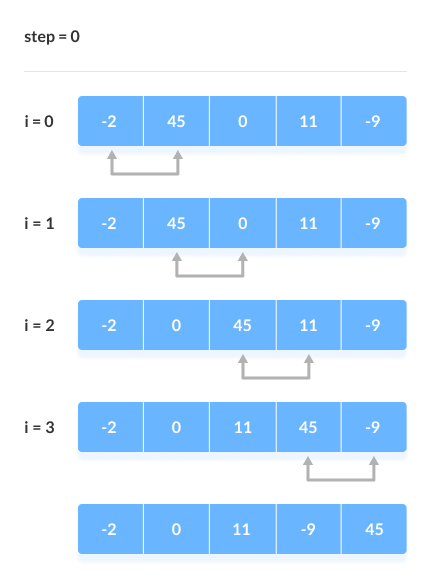
If you're more of a visual learner, here is an example of how a bubble sort would work with an array of [-2, 45, 0, 11, -9]
A Ruby Implementation
Let's code our own bubble sort!
# Our method will take an array as a parameter
def bubble_sort(array)
array_length = array.size
return array if array_length <= 1
end
The first lines of our code return the original array if it has zero or one element since it will already be sorted.
Next, we need to create a loop that will iterate through the array and compare each element with the next one.
# Our method will take an array as a parameter
def bubble_sort(array)
array_length = array.size
return array if array_length <= 1
loop do
# we need to create a variable that will be checked so that we don't run into an infinite loop scenario.
swapped = false
# subtract one because Ruby arrays are zero-index based
(array_length-1).times do |i|
end
end
end
Let's break down what's happening here. We are using Ruby's generic loop, which is essentially the same as doing while (true). You could also use a while loop, but you'd need to set your loop check variable outside of the loop and set it to true instead of false.
Once inside our loop, we set swapped to false, which will let the program know when to exit the loop. From there, we will start iterating through the elements in our array. For simplicity's sake, let's work with the same array from our previous example.
[11,5,7,6,15]
The array_length-1 variable is going to equal 4 (5 elements - 1), so the line
(array_length - 1).times do |i|
will essentially be 4.times do |i| where i will start at 0. Let's finish out our method.
# Our method will take an array as a parameter
def bubble_sort(array)
array_length = array.size
return array if array_length <= 1
loop do
# we need to create a variable that will be checked so that we don't run into an infinite loop scenario.
swapped = false
# subtract one because Ruby arrays are zero-index based
(array_length-1).times do |i|
if array[i] > array[i+1]
array[i], array[i+1] = array[i+1], array[i]
swapped = true
end
end
break if not swapped
end
array
end
Inside of our nested iterator, we compare the adjacent elements. For example, the first iteration would compare the elements at array[0] and array[1], and if the number at array[1] is greater than the number at array[0], we will swap the values.
Our nested iterator will continue to loop (array_length-1).times.
When do we want to exit the loop? Remember, we have the outer loop in which we are setting swapped = false. We want to exit this loop when the inside iterator can move through all adjacent elements and not have to swap (i.e., swapped remains false.)
So, we will break if not swapped and know that we have successfully sorted the array elements.
Finally, we return our sorted array.
If you've been coding along, go ahead and try running the program in your terminal. Here is what my ruby-sorting.rb file looks like:
def bubble_sort(array)
array_length = array.size
return array if array_length <= 1
loop do
# we need to create a variable that will be checked so that we don't run into an infinite loop scenario.
swapped = false
# subtract one because Ruby arrays are zero-index based
(array_length-1).times do |i|
if array[i] > array[i+1]
array[i], array[i+1] = array[i+1], array[i]
swapped = true
end
end
break if not swapped
end
array
end
unsorted_array = [11,5,7,6,15]
p bubble_sort(unsorted_array)
Running ruby ruby-sorting.rb in the terminal produces the following:
[5, 6, 7, 11, 15]
Cool! It works! If you're still having a hard time visualizing what is going on, try adding some additional log statements. For example, you could add a puts "iteration: #{i}" within the (array_length-1).times do |i| line. Here is the output you should have if you do that:
➜ Documents ruby ruby-sorting.rb
iteration: 0
iteration: 1
iteration: 2
iteration: 3
iteration: 0
iteration: 1
iteration: 2
iteration: 3
iteration: 0
iteration: 1
iteration: 2
iteration: 3
[5, 6, 7, 11, 15]
I added some spacing for visualization purposes, but as you can see, our algorithm looped through the array three times -- exactly what we would have expected given our previous work. Nice!
So, when would I use bubble sort in real life?
Almost never. Sorry to break your bubble, but the bubble sort algorithm is not very practical IRL, which is why Barack Obama correctly said that the bubble sort method would not be what you'd choose if you needed to efficiently sort an array with a million elements.
How do we measure an algorithm's efficiency? One common technique is to look at the "Big-O notation" -- this represents the worst-case performance so that algorithms can be compared. For example, an algorithm with a Big-O of O(1) means that the worst-case run time is constant as the number of elements, "n", grows, whereas an algorithm with a Big-O notation of O(n) means that the worst-case run time increases linearly as n grows. This means that if you had an array with 100 elements and had to choose between a sorting algorithm that was O(n) and O(1), you would choose the O(1) algorithm because O(1) definitely beats O(100).
Now, back to the bubble sort. The bubble sort has a worst-case and average complexity of O(n^2). This means that its efficiency decreases dramatically as the number of elements grows.
Interested in learning more about Big-O notation? Feel free to check out one of my earlier posts.
Further, there are other algorithms with worst-case O(n^2) complexity that have been shown to perform better on random lists -- most notably, the insertion sort.
You still haven't explained the rabbits and turtles thing.
Consider our original array: [11,5,7,6,15]
Elements, like the 11, that need to move toward the end of the list can move quickly because it can take part in successive swaps. However, elements that need to move towards the beginning cannot move faster than one step per pass. For these reasons, the 11 would be considered a "rabbit" and the 6 a "turtle".
What's next?
Even if not practical, the bubble sort may come up during an interview, and it's generally a good place to start when learning sorting algorithms. Later in this series, we'll discuss and dissect more efficient algorithms that we can compare back to the bubble sort. Apropos of nothing, it has a fun name.

Written by
Julie KentJulie is an engineer at Stitch Fix. In her free time, she likes reading, cooking, and walking her dog.