Using DynamoDB in Your Rails App
At its core, DynamoDB is a NoSQL database that offers key-value and document data structures. Let's unpack this. I imagine that most of the developers reading this are quite familiar with traditional relational database systems, which involve well-defined schemas and data normalized into tables, rows, and columns. Between these tables, there are "relationships" utilizing foreign keys. In contrast, DynamoDB is schemaless. While every table must have a primary key, there are no other constraints on other non-key attributes. When would this be beneficial, you ask? Well, let's learn why Amazon created DynamoDB.
Amazon announced plans to release DynamoDB for public use in 2012. Amazon had originally developed Dynamo internally after the 2004 holiday season, when several of their applications failed due to the high amount of traffic.
When should you consider utilizing DynamoDB?
DynamoDB is a solid option for applications that need to support a very large number (in the thousands+) of concurrent users and, therefore, tens of thousands of reads/writes per second. For example, social networks, games, and IoT devices might be good candidates for DynamoDB; for example, Lyft, Airbnb, and Redfin utilize Dynamo. Even if adoption is light at first, and the need for performance isn't immediately necessary, starting with DynamoDB may be advantageous vs. a traditional SQL database, such as Postgres, if you will eventually build for scale. However, if you're building out a data warehouse or OLAP application that users will be frequently querying, a schemaless database is probably not the best design choice. Furthermore, whereas RDMS are optimized for storage, DynamoDB is optimized for compute. Amazon touts that DynamoDB can deliver single-digit millisecond performance at any scale, as well as handle 10 trillion+ requests per day, with peaks of 20 million+ requests per second. Wow!
Additionally, AWS offers a suite of other features that can make DynamoDB a great fit for applications requiring data retention and/or security.
-
Encryption at rest: DynamoDB secures all of your data in an encrypted table, including the primary key. Users can choose three options: an AWS-owned customer master key (CMK), an AWS-managed CMK (i.e., the key is stored in your account and managed by the AWS Key Management Service), or a customer-managed CMK (i.e., the key is stored in your account and created/owned/managed by you.) The cool thing is that each table can utilize a different option. To read more about encryption at rest, here are the official AWS docs.
-
On-demand backups/point-in-time recovery: DynamoDB allows you to restore a table to any point in time during the last ~30 days. So long are the days of worrying about accidental writes or deletes!
The basics of DynamoDB
DynamoDB has three core components: tables, items, and attributes. Let's break each of these down.
- Table: a collection of items
- Item: a collection of attributes
- Attribute: a fundamental data element that need not be broken down any further.
For example, if I am making an application to manage rental properties, I might have a table called "Houses" with the following items:
{
"HouseID": 1,
"AddressLine1": "123 Main St",
"City": "Atlanta",
"State": "GA",
"Zip": 30322,
"Rented": true,
"Tenant": "John Smith"
}
{
"HouseID": 2,
"AddressLine1": "456 Square St",
"City": "Nashville",
"State": "TN",
"Zip": 37211,
"Rented": true,
"Tenant": "Mary Jane"
}
HouseID, AddressLine1, City, State, Zip, Rented and Tenant are all attributes of the items. You can liken an item to a row and an attribute to a column in a traditional SQL database. However, I suggest trying to avoid comparing a NoSQL database, such as DynamoDB, with a traditional SQL database, as they are very different beasts.
Notice that each item has a unique primary key (DynamoDB supports both single partition keys and composite primary keys). However, other than HouseID, the Houses table is schemaless. Thus, the attributes and data types need not be defined ahead of time, unlike a traditional SQL database, which would require Zip to be defined in schema with the integer type specified.
You might be wondering how indexes work with DynamoDB. If so, this is a great question! Let's pretend I want to create an index on the rented and zip attributes of my Houses table (i.e., given the zip code, get all rented properties in that zip code). If I were using a SQL database, I might create a migration that looks like this:
CREATE INDEX RentedAndZipIndex
ON Houses (rented, zip);
In contrast, if I were using DynamoDB, I would want to set up a secondary index. To do this, I must specify a partition key and a sort key. In this example, zip is the partition key and rented is the sort key. There is a lot more to learn about indexes with DynamoDB, but for the sake of this article, we will leave it here. If you're interested in learning more, you can read more here.
Utilizing DynamoDB with Ruby and Ruby on Rails
AWS offers SDKs in a number of languages for DynamoDB (i.e., Java, JavaScript, Node.js, .NET, PHP, Python, and Ruby, currently.) To use DynamoDB with Ruby, you have two options:
- Download DynamoDB locally; if you just want to test applications, this is a great option! When you're ready to move on to production, you can remove the local endpoint and point to the web service.
- Utilize the DynamoDB web service, which will require an AWS access key and creds.
To interact with DynamoDB, you will likely want to download the CLI. Otherwise, you can utilize the console or just the API.
Finally, for the purpose of this series, you will need to have installed Ruby, as well as the AWS SDK for Ruby.
For Rails, there is a nifty gem that you can add to your project. It is called Dynamoid. However, you will still need AWS credentials.
Rails Example
Step 1: Setup
In your Gemfile, add the following gems and run bundle install:
gem 'dynamoid'
gem 'aws-sdk'
Next, create a new file aws.rb in the config/initializers directory and add the following:
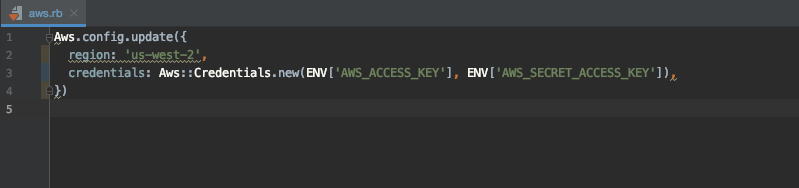
Note: You should use environment variables to hold credentials. Never hard-code these into your project!
Step 2: Defining a Document
For this example, I created a house.rb file in the app/models directory that looks like this:
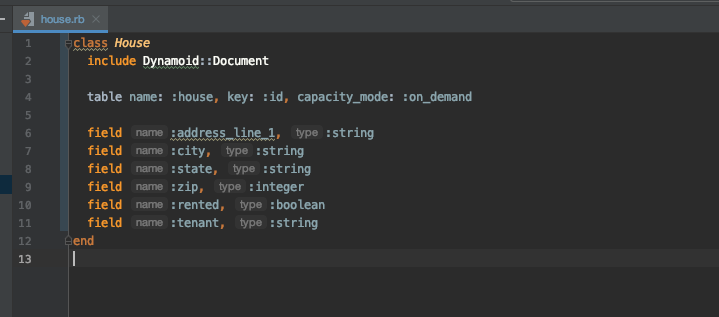
Let's walk through what we have here.
- You must always include
include Dynamoid::Documentwhen defining your tables. - On line 4, I am defining the table name, key, and capacity mode. The Dynamoid gem has sensible defaults, so technically, you do not need to include any of the above. However, defining them will override the defaults. You can also define
read_capacityandwrite_capacity. However, since I have definedcapacity_modeason_demand, these options would be ignored sinceon_demandcapacity mode is telling AWS to automatically scale up or down. - Next, I am defining the fields for my table. You must define all of the fields on the model, as well as the data type, although it will be assumed to be
stringif omitted.)
The dynamoid gem comes with a nifty rake task to create your table.
rake dynamoid:create_tables
Step 3: Interacting with Objects
While some of this may look foreign to you, I have good news! The great part about the dynamoid gem is that a lot of the other features you're used to with Active Record work very much the same way.
Associations
For example, Dynamoid supports a number of associations: has_many, has_one, has_and_belongs_to_many, and belongs_to can all be defined just as you would normally with ActiveRecord. You could imagine my rental properties app having another document table called Lease, so on the House table, I might define something like this:
has_one :lease
and on the Lease table:
belongs_to :house
Validations
Dynamoid also bakes in ActiveModel validations, so you're all set there! The documentation is available here.
Callbacks
before_ or after_ callbacks are available for save, update, destroy actions, so I could define something like this in my lease.rb:
before_save :validate_signature
Creation
Again, the syntax utilized to create objects will look basically identical to what you're used to with ActiveRecord. I could do something like the following:
h = House.new(address_line_1: "123 Main St", city: "Cool City", state: "Iowa", zip: 52302)
h.rented = true
h.save
Or I could simply use the .create method:
House.create(address_line_1: "123 Main St", city: "Cool City", state: "Iowa", zip: 52302)
Querying
I know that I am sounding like a broken record, but can you guess how querying works? You got it, just like ActiveRecord.
.findwill take an ID.wherewill take any number of matching criteria.find_by_xwherexis an attribute.
Want More?
There is a lot more to learn about the Dynamoid gem, but hopefully, this is enough to get you started playing around. I encourage you to check out the official GitHub page here to read more about the features available to you!
Next up
Well, there is a LOT to digest here! Hopefully, you feel a bit more knowledgeable about what it means when someone says 'NoSQL' and why DynamoDB might be a good choice for projects needing a schemaless database. Additionally, we've walked through the basic setup of utilizing the dynamoid gem with your Rails project.
In the next article of this series, we'll get DynamoDB setup locally and try out some of the features of the Ruby SDK.

Written by
Julie KentJulie is an engineer at Stitch Fix. In her free time, she likes reading, cooking, and walking her dog.