Why every web developer should explore machine learning
I don't have kids yet, but when I do, I want them to learn two things:
- Personal finance
- Machine learning
Whether or not you believe that the singularity is near, there's no denying that the world runs on data. Understanding how that data is transformed into knowledge is critical for anyone coming of age these days – and even more so for developers.
This is the first article in a series that will attempt to make machine learning (ML) accessible to full-stack Ruby developers. By understanding the ML tools at your disposal, you'll be able to help your stakeholders make better decisions. Future articles will focus on individual techniques and practical examples, but in this one, we're setting the stage – showing you a map and placing a pin that says "you are here."
Humble Beginnings

Artificial intelligence (AI) and machine learning are nothing new. Back in the 1950s, Arthur Samuel built a computer program that could play checkers. He used "alpha-beta pruning" – a common search algorithm.
The 1960s saw the advent of multi-layered neural networks and the nearest-neighbor algorithm, which is used to find optimal pathing in warehouses.
So if AI is so old, why are AI startups so trendy? In my opinion, there are two reasons for this:
- Computing power (see Moore's Law)
- The amount of data being added to the internet every day
There are two statistics related to the amount of data being created on a daily basis that blow my mind every time I think about them:
- As of 2018, we are producing 2.5 quintillion bytes of data every day. No doubt this number has only increased since this Forbes article was published.
- Over the last two years alone, 90% of the data in the world was generated.
Together, what this means is that (1) the hardware necessary to store data and run algorithms continues to become more affordable and (2) the amount of data available to train the ML models is increasing at a crazy-fast pace.
Every day we are interacting with, being influenced by, and contributing to the world of artificial intelligence and machine learning. For example, you can thank (or blame) algorithms for the following:
- Your credit line
- Helping diagnose illness
- Maybe even whether or not you got the job
- Helping you find the most efficient route given current traffic conditions
- Alexa understanding exactly what you mean when you tell her you just sneezed
- Spotify introducing you to your new favorite song
The reason I brought up my hypothetical future kids is this: I want them to understand how their digital lives influence their "real" lives, the implications of their data privacy decisions, and how to form their own opinions of when they should trust the machine vs. when they shouldn't.
In the remainder of this post, I want to give an overview of the three kinds of machine learning that I've studied: supervised learning, unsupervised learning, and reinforcement learning. We'll talk about what makes each approach unique and the problems each is especially good at solving.
Supervised Learning
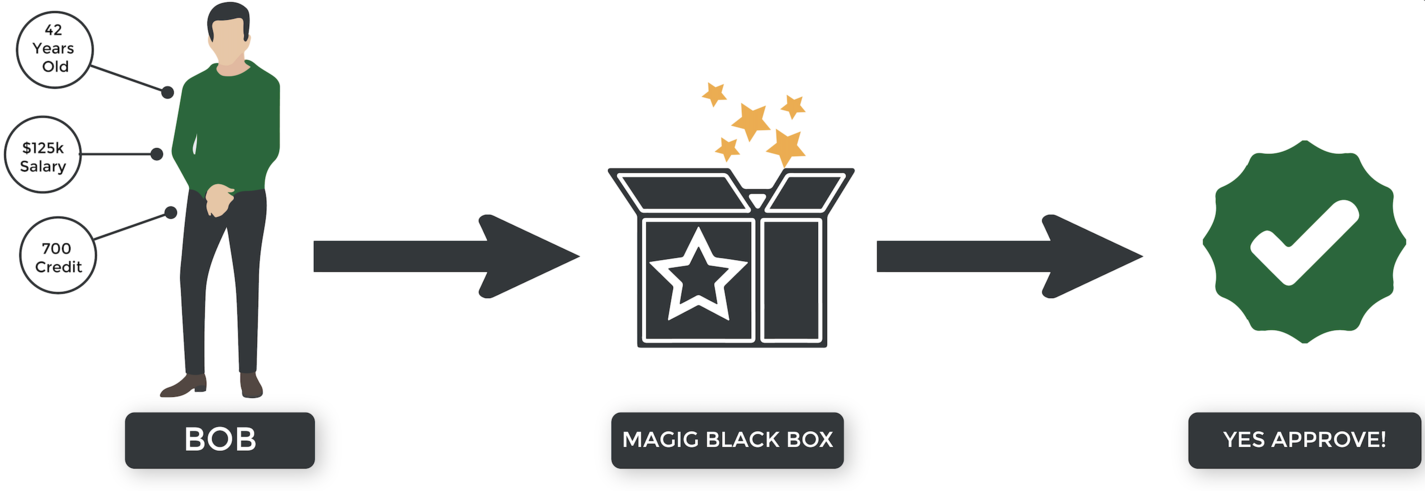
Supervised learning is... well, supervised by humans. :) Imagine that we're building a supervised learning system to decide who gets approved for a mortgage. Here's how it might work:
- The bank compiles a dataset that maps customer attributes (age, salary, etc.) to outcomes (repayment, default, etc.).
- We train our system using the data.
- The system uses what it learns to guess future outcomes based on an applicant's attributes.
- If the algorithm guesses correctly, we tell it, "Great job! You're right." But if it's wrong, we tell it, "No, you're incorrect. Please improve and try again."
This example is considered a "classification" problem because the output of the algorithm is a category – in this case, approved or not approved. Other examples of classification problems include deciding whether or not:
- a person has an illness
- an x-ray has a broken bone
- an e-mail is spam
If you're curious to learn more about the math behind ML classification algorithms, Google any of these: naive Bayes classifiers, support vector machines, logistic regression, neural networks, random forests.
In addition to classification problems that render a "yes/no" outcome, supervised learning can also be utilized to solve regression problems – here, we make a prediction on a continuous scale, for example:
- the future value of a stock
- the probability that the New England Patriots win the Super Bowl
- the average salary a company needs to offer a candidate for them to accept
Examples of algorithms used for supervised regression problems include linear regression, non-linear regression, and Bayesian linear regression.
Unsupervised Learning
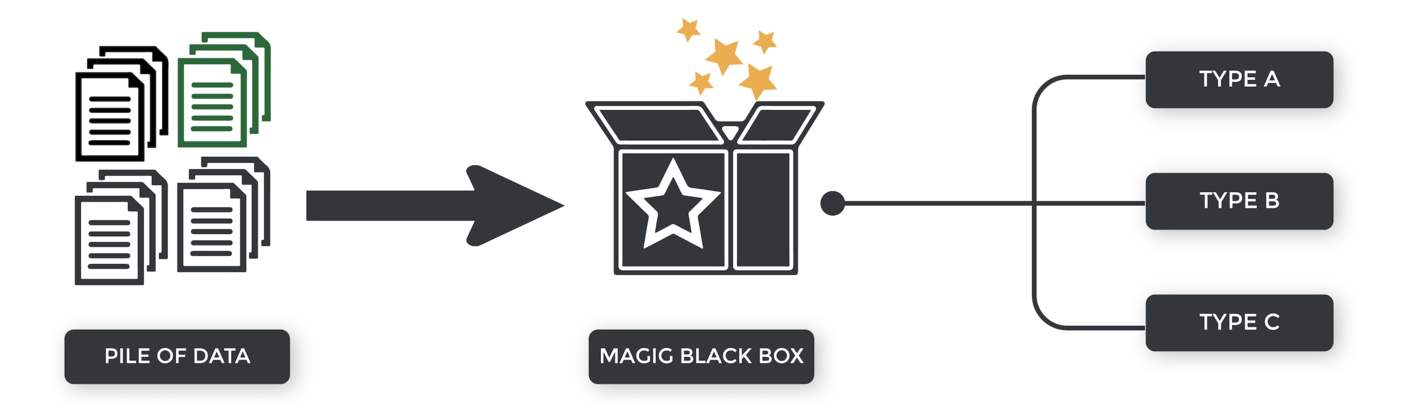
With our supervised learning example, we predefined the classification categories. The mortgage applicant was either approved or denied.
With unsupervised learning, we don't provide the categories. They're not available to us. The algorithm must come up with its own conclusions.
Why would we want to use an unsupervised approach?
-
Sometimes we don't know categories beforehand. Much of the data floating around the internet is unstructured – i.e., lacking labels.
-
Other times, we don't know what we're looking for, so we can ask the algorithm to find patterns/features that can be useful for categorization.
Another way to handle unstructured data with machine learning is to simply have humans look at it and manually label it. There are lots of companies that hire workers to manually classify data: labeling data.
Approaches to Unsupervised Learning
Two techniques that are commonly used in unsupervised learning are association and clustering.
Association: Imagine that you're Amazon. You have a lot of customer data, purchase history, etc. By using unsupervised learning, you could partition customers into "types of shoppers" – maybe figuring out that those who buy pink umbrellas are more likely to also purchase Matcha tea.
Clustering: Clustering looks at your data and partitions it into a specified number of groups, or clusters. For example, maybe you have a bunch of housing data and you want to see if there are any features (possibly crime data?) that can predict what neighborhood the home is in. Or, techniques like cosine similarity can be used for text classification (e.g., is this article about tennis, cooking, or space?).
If you're interested in learning more about specific unsupervised learning techniques, Google search k-means clustering, cosine similarity, hierarchical clustering, and k-nearest-neighbor clustering.
Reinforcement Learning

This subset of machine learning is commonly used in games because it utilizes goal-oriented algorithms. Unlike supervised learning, each decision is NOT independent – given a current input, the algorithm makes a decision and the next input depends on this decision.
Just like I give my dog a pat on the head when he stops incessantly barking when the doorbell rings or put him in his kennel when he won't shut up, reinforcement algorithms are rewarded when making a goal-optimizing decision (e.g., scoring the max number of points) and penalized when making a poor one.
The obvious applications for reinforcement learning algorithms include:
- games like chess and Go (I highly recommend the AlphaGo documentary on Netflix, if you haven't seen it already.)
- robotics (teaching bots to complete desired tasks)
- autonomous vehicles
- robo-advisors that are trained to beat the stock market
If you're interested in learning more about the algorithms behind reinforcement learning, Google search Q-learning, state-action-reward-state-action (SARSA), DQN, and the asynchronous advantage actor critic.
Remember to learn more
I hope that these examples have helped you gain a grasp on machine learning techniques and how each is used to influence the crazy world we live in today. While I sometimes find myself overwhelmed with all that there is to learn, starting somewhere is better than doing nothing, and remember that much of this is actually not very new at all – we are just hearing about it more as data becomes more available and processing power cheaper.
Editor's note: This post was originally published in March 2020 and has been updated for accuracy.

Written by
Julie KentJulie is an engineer at Stitch Fix. In her free time, she likes reading, cooking, and walking her dog.