Cross-cluster associations in Railsh
One of the beauties of the Rails framework is the ability to utilize Ruby on Rails associations in your models. These associations allow you to access collections of records in your code with pleasant syntax, abstracting away the need to write underlying SQL queries. That abstraction holds as long as all your data lives in one place. The moment your tables are spread across separate database clusters, certain association types stop working.
This article walks through exactly where that boundary is and what Rails provides to work within it. We start with why the problem occurs and which associations in Rails are affected, and move into the database configuration and model hierarchy that supports multiple clusters and many to many relationships. From there we'll cover how different different data access patterns each interact with that decomposition.
If you're looking for a Rails associations tutorial that covers multi-database setups specifically, this is it. We will also discuss many other things, so stick around.
Why databases end up in different clusters
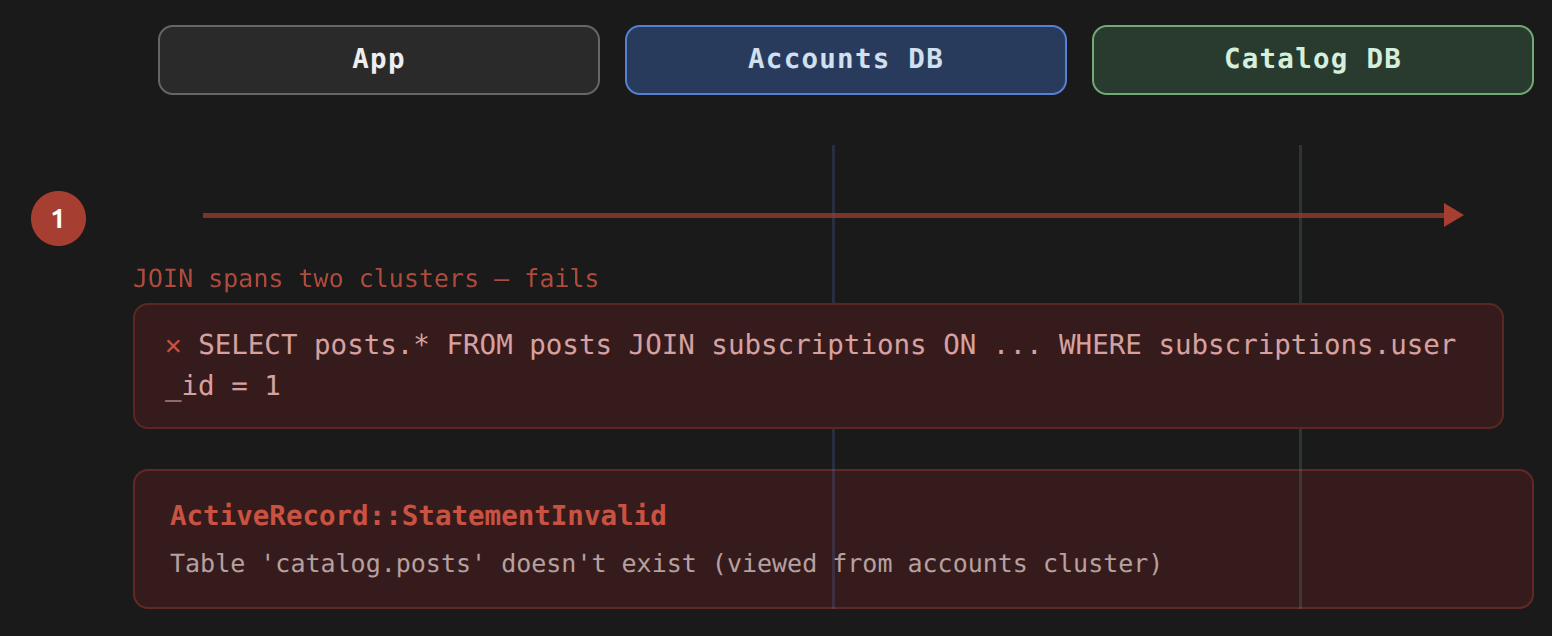
When a Rails application stores all its data in a single database, Active Record associations are handled transparently, and you never think about the underlying SQL. The moment your data lives across multiple database clusters, that transparency breaks down. A JOIN requires both tables to exist in the same database server. Attempting one across clusters produces an ActiveRecord::StatementInvalid error like this:
ActiveRecord::StatementInvalid (Table 'people_cluster.humans' doesn't exist)
This isn't a configuration mistake. It's a hard physical constraint: database servers cannot JOIN against tables they don't host. We have this problem in has_many :through and has_one :through associations, because those are the association types that generate intermediate JOIN queries. Direct has_many or belongs_to relationships don't require a join so they work across clusters without any modification.
Understanding when you'll hit this boundary is the first step. If a User lives in the accounts database and a Post lives in the content database, User has_many :posts works fine. But if you add an intermediate Subscription model in the billing database and define User has_many :posts, through: :subscriptions, Rails will attempt to join subscriptions and posts in a single query. That's where the cluster boundary becomes a problem.
The three-tier database configuration
Before writing any model code, the database configuration needs to reflect the multi-cluster layout. Rails uses a three-tier structure in config/database.yml for this purpose. Each top-level environment key contains nested database names, and each of those contains the connection details for that cluster.
# config/database.yml
default: &default
adapter: postgresql
pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %>
development:
primary:
<<: *default
database: myapp_primary_dev
accounts:
<<: *default
database: myapp_accounts_dev
migrations_paths: db/accounts_migrate
content:
<<: *default
database: myapp_content_dev
migrations_paths: db/content_migrate
production:
primary:
<<: *default
database: myapp_primary_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
accounts:
<<: *default
database: myapp_accounts_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
content:
<<: *default
database: myapp_content_prod
username: <%= ENV['DB_USER'] %>
password: <%= ENV['DB_PASSWORD'] %>
The migrations_paths key is non-optional if you want Rails generators and db:migrate to route migrations to the correct directory. Without it, all migrations default to db/migrate and get applied to the primary database. Each secondary database should also have a corresponding abstract record class that Rails models inherit from. Generators handle this automatically when you pass the --database flag:
rails generate model Subscription plan:string --database accounts
This produces an AccountsRecord class if one doesn't already exist, and the generated Subscription model inherits from it.
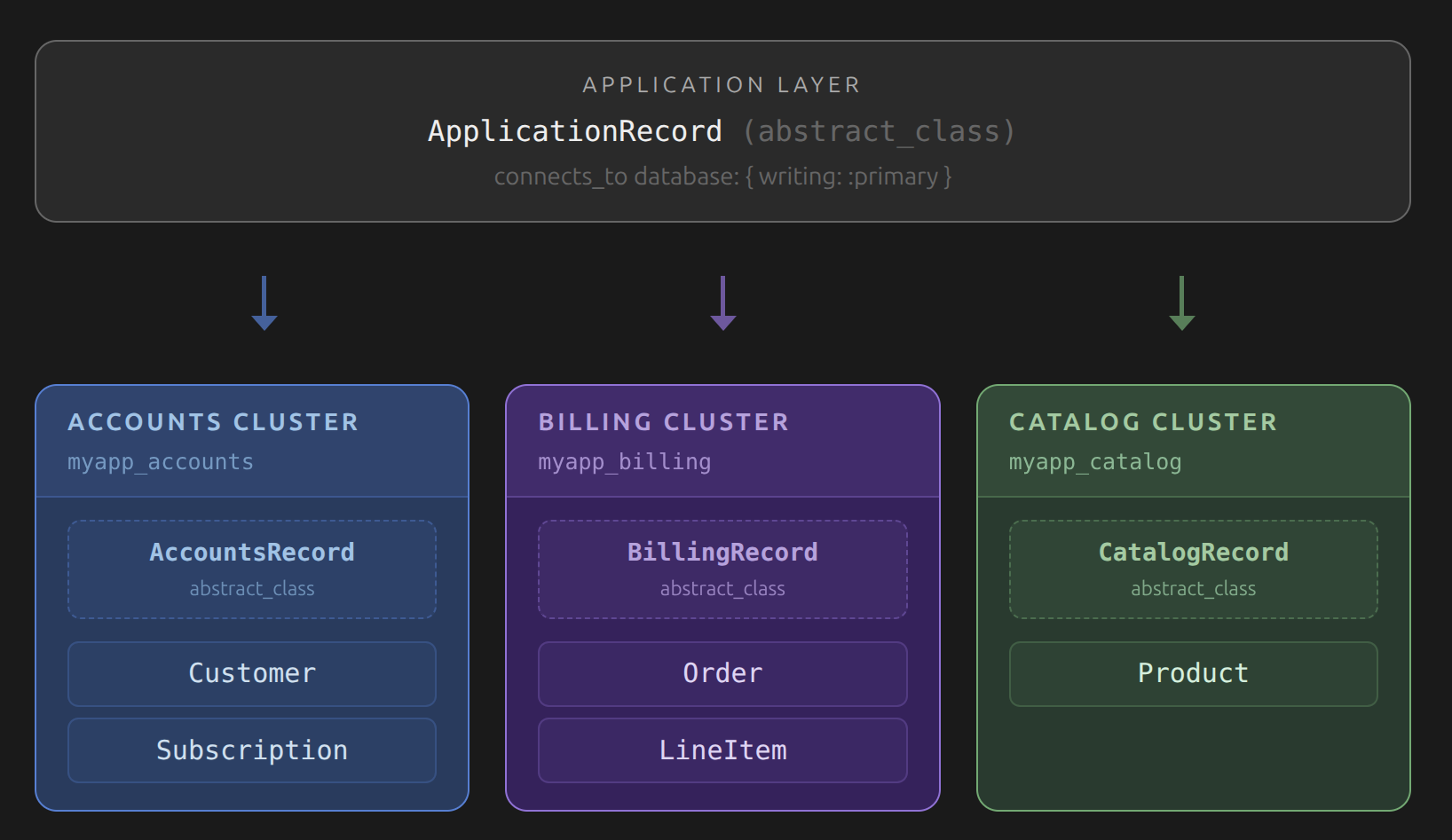
Abstract record classes and connection routing
The abstract record classes are the mechanism Rails uses to route queries to the correct cluster. Each one calls connects_to to declare which database it maps to for writing and reading operations. Your application will typically have three layers in this hierarchy.
# app/models/application_record.rb
class ApplicationRecord < ActiveRecord::Base
self.abstract_class = true
connects_to database: { writing: :primary, reading: :primary }
end
# app/models/accounts_record.rb
class AccountsRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :accounts, reading: :accounts }
end
# app/models/content_record.rb
class ContentRecord < ApplicationRecord
self.abstract_class = true
connects_to database: { writing: :content, reading: :content }
end
The User model is a good anchor for understanding this hierarchy. It lives in the accounts cluster and inherits from AccountsRecord. Models in the content cluster inherit from ContentRecord. Everything else inherits from ApplicationRecord and hits the primary database. This inheritance chain is how Active Record determines which connection pool to use when executing a query. It walks up the class hierarchy until it finds a class that has called connects_to.
A common mistake is calling establish_connection on individual models instead of using abstract classes. Each establish_connection call opens a separate connection pool. If you have 50 models in the accounts database, each calling establish_connection, you end up with 50 connection pools pointing at the same server. Abstract classes solve this by sharing a single pool across all models that inherit from them.
How cross-cluster associations in Rails actually work
The disable_joins: true option is the direct mechanism for making through associations work when the involved tables live in different clusters. Rails has_many is the most commonly used association type, and it's the one most directly affected by cluster boundaries. When Rails encounters this option on an association, it abandons the single JOIN query strategy and instead issues two (or more) sequential SELECT statements, piping the IDs from the first query into a WHERE ... IN (...) clause in the second.
Here's a concrete model setup spanning three clusters. The model setup below is a many-to-many relationship, a User connects to Posts through Subscriptions, and it's the pattern that most directly exposes the cross-cluster problem.
# app/models/user.rb - lives in the accounts database
class User < AccountsRecord
has_many :subscriptions
has_many :posts, through: :subscriptions, disable_joins: true
end
# app/models/subscription.rb - lives in the accounts database
class Subscription < AccountsRecord
belongs_to :user
has_many :posts
end
# app/models/post.rb - lives in the content database
class Post < ContentRecord
belongs_to :subscription
end
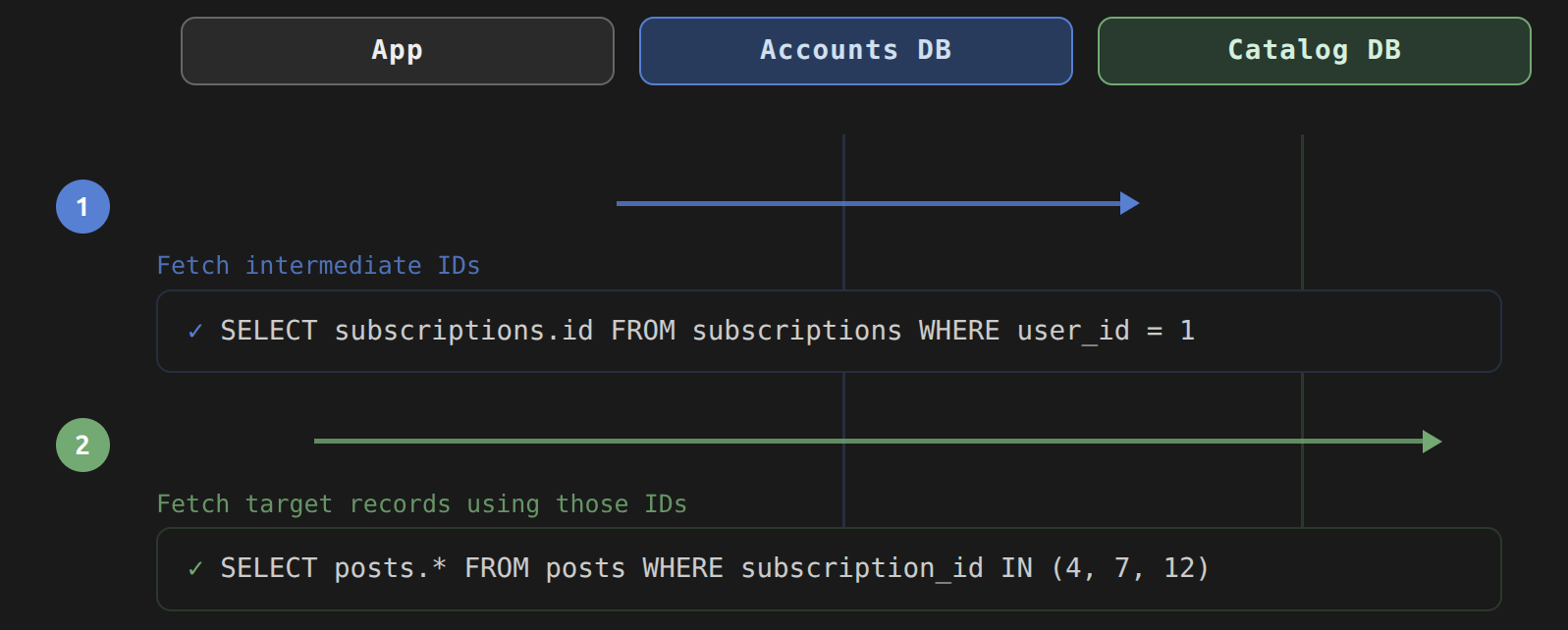
When you call user.posts, Rails generates this pair of queries instead of a single JOIN:
-- Query 1: fetch subscription IDs from the accounts cluster
SELECT "subscriptions"."id"
FROM "subscriptions"
WHERE "subscriptions"."user_id" = 1
-- Query 2: fetch posts from the content cluster using those IDs
SELECT "posts".*
FROM "posts"
WHERE "posts"."subscription_id" IN (4, 7, 12)
The first query runs against the accounts database to collect a primary key. The second runs against content. Rails resolves the relationship by following the foreign keys, user_id on subscriptions and subscription_id on posts, across the two clusters. The first query collects the primary key values from subscriptions, then passes them into the IN clause of the second query. Neither query attempts a cross-cluster join. Rails assembles the final result set in application memory.
The same option works identically on has_one :through:
# app/models/user.rb
class User < AccountsRecord
has_one :profile
has_one :avatar, through: :profile, disable_joins: true
end
# app/models/profile.rb - accounts database
class Profile < AccountsRecord
belongs_to :user
has_one :avatar
end
# app/models/avatar.rb - content database
class Avatar < ContentRecord
belongs_to :profile
end
user.avatar will execute two queries: one to get the profile_id, another to fetch the avatar record from the content cluster.
When disable_joins must be set explicitly
Rails does not automatically detect cluster boundaries and insert disable_joins for you. Association loading in Active Record is lazy. The SQL for an association is determined at the point the association is defined on the model, not when it's actually triggered. By the time user.posts executes, Rails has already decided whether to use a JOIN or separate queries based on the association declaration.
This means every through association that crosses a cluster boundary needs disable_joins: true on the declaration.
A practical way to audit your models is to look for any through: association where the source model and the target model inherit from different abstract record classes. If User < AccountsRecord and Post < ContentRecord, then has_many :posts, through: :subscriptions needs disable_joins: true regardless of where Subscription lives.
Eager loading across clusters
The disable_joins option affects how associations are loaded, but it does not change how eager loading strategies interact with cross-cluster data. Understanding this distinction matters for avoiding N+1 queries in multi-database setups.
eager_load is off the table for cross-cluster associations. It generates a LEFT OUTER JOIN, which has the same physical limitation as a regular JOIN , both tables must be on the same server. If you attempt User.eager_load(:posts) where posts live in a different cluster, you will get the same StatementInvalid error.
preload is the correct strategy. It issues separate queries for each association and assembles the relationship in Ruby. This is structurally identical to what disable_joins does for a single record. The difference is scale: preload batches the second query across all loaded parent records.
# This works across clusters.
# Query 1: SELECT "users".* FROM "users"
# Query 2: SELECT "posts".* FROM "posts" WHERE "posts"."subscription_id" IN (...)
users = User.preload(:posts).all
users.each do |user|
user.posts.each { |post| puts post.title } # No additional queries fired
end
includes will work in cases where it delegates to preload internally, which it does by default when there are no conditions referencing the associated table. If you add a .where clause that touches the associated table's columns, includes switches to eager_load behavior, and will fail across clusters. When in doubt about which strategy includes will choose, be explicit and use preload directly.
# includes delegates to preload here, works across clusters
User.includes(:posts).all
# includes switches to eager_load because of the where clause, fails across clusters
User.includes(:posts).where("posts.published = ?", true)
# Use preload + a separate where for cross-cluster filtering
User.preload(:posts).all.select { |u| u.posts.any?(&:published?) }
# Or filter in application code after loading
Scoped associations and cross-cluster filtering
One of the more subtle interactions in multi-database setups is scoped associations. When you define a scope on a has_many that crosses clusters, the scope's SQL runs against the target database, not the source.
class User < AccountsRecord
has_many :subscriptions
has_many :published_posts,
-> { where(published: true) },
through: :subscriptions,
source: :posts,
class_name: "Post",
disable_joins: true
end
The where(published: true) clause gets appended to the second query, the one that runs against the content database. This is correct behavior, and it means your scopes can reference columns on the target table without issue. What you cannot do is reference columns from the intermediate table in that scope, because the intermediate query has already completed by the time the scoped query executes.
# This will fail because subscriptions.active is not a column in the content database
has_many :active_posts,
-> { where("subscriptions.active = ?", true) },
through: :subscriptions,
source: :posts,
disable_joins: true
Filter intermediate records by adding a scope to the intermediate association instead:
class User < AccountsRecord
has_many :active_subscriptions, -> { where(active: true) }, class_name: "Subscription"
has_many :active_posts, through: :active_subscriptions, source: :posts, disable_joins: true
end
Now the filtering on subscriptions.active happens in the first query, against the accounts database, and only the IDs from active subscriptions get passed to the second query.
Horizontal sharding and cross-shard associations
Splitting one logical database across multiple servers based on a partition key like tenant_id introduces a second dimension to the cross-cluster problem. The disable_joins mechanism still applies, but the connection routing becomes more involved.
Rails provides connected_to for switching between shards within a request:
ActiveRecord::Base.connected_to(role: :writing, shard: :shard_one) do
User.find(1) # Hits shard_one
end
When associations span both clusters and shards, you need to ensure both the shard context and the disable_joins option are in place. A User on shard_one accessing posts that live in a separate content database still needs the same two-query decomposition.
Rails 8 added introspection methods that make reasoning about shard topology easier at runtime:
class ShardedBase < ActiveRecord::Base
self.abstract_class = true
connects_to shards: {
shard_one: { writing: :shard_one },
shard_two: { writing: :shard_two }
}
end
class User < ShardedBase; end
User.shard_keys # => [:shard_one, :shard_two]
User.sharded? # => true
ShardedBase.connected_to_all_shards do
User.current_shard # Yields :shard_one, then :shard_two
end
connected_to_all_shards is particularly useful for background jobs that need to process records across every shard. It iterates over each shard in sequence, switching the connection context for each block execution.
For tenant-based sharding, the lock: true default on shard switching prevents accidental tenant hopping mid-request. This is a safety mechanism: once a request is routed to a tenant's shard, the application code cannot switch to a different tenant's shard without explicitly passing lock: false. Cross-cluster associations within a single tenant's shard still use disable_joins for associations that touch a different database cluster.
Testing cross-cluster associations
Testing multi-database setups requires that your test environment mirrors the production database topology. Rails' test framework supports this, but the configuration must be explicit.
Each database in database.yml needs a test environment block. Fixtures and factory-based test data must target the correct database. If a User factory creates a record in the accounts database and a Post factory creates one in content, the association between them only works if both records exist in their respective databases within the same test transaction.
Rails wraps each test in a transaction by default, but that transaction is per-connection. With multiple databases, each connection gets its own transaction. This means test cleanup (the automatic rollback at the end of each test) happens independently on each database. If your test writes a User to accounts and a Post to content, both will be rolled back, but only if the test framework knows about both connections.
The fixtures declaration handles this automatically when models inherit from the correct abstract class. For factory-based setups (FactoryBot, Fabricator), ensure each factory's create strategy hits the right database by letting the model's own connects_to routing do the work.
# spec/factories/users.rb
FactoryBot.define do
factory :user do
# User inherits from AccountsRecord and writes to accounts DB automatically
name { Faker::Name.name }
end
end
# spec/factories/posts.rb
FactoryBot.define do
factory :post do
# Post inherits from ContentRecord and writes to content DB automatically
association :subscription
title { Faker::Lorem.sentence }
end
end
To verify that cross-cluster associations are firing the expected number of queries, subscribe to the sql.active_record notification:
# spec/support/query_counter.rb
module QueryCounter
def assert_query_count(expected, &block)
count = 0
callback = ->(_name, _start, _finish, _id, payload) do
count += 1 unless payload[:name] == "SCHEMA" || payload[:sql].start_with?("EXPLAIN")
end
ActiveSupport::Notifications.subscribed(callback, "sql.active_record", &block)
assert_equal expected, count, "Expected #{expected} queries, got #{count}"
end
end
A has_many :through with disable_joins: true on a single record should produce exactly 2 queries. If you see 1, the join is still being attempted (and will fail in production against separate servers). If you see N+1, eager loading isn't working as expected.
Some caveats
disable_joins solves the association loading problem, but it does not extend to query chaining. You cannot chain .where, .order, or .group clauses that reference columns across clusters on a single Active Record relation:
# This does not work, you cannot filter products by order columns across clusters
customer.purchased_products.where("orders.total > ?", 100)
For queries that need to filter or sort based on data in multiple clusters, decompose them manually. Fetch the IDs or values you need from one cluster, then use them as inputs to a query against the other:
high_value_order_ids = Order.where(customer_id: customer.id)
.where("total > ?", 100)
.pluck(:id)
line_item_product_ids = LineItem.where(order_id: high_value_order_ids).pluck(:product_id)
products = Product.where(id: line_item_product_ids)
This is the same decomposition that disable_joins performs internally, but done explicitly so you can apply filtering at each stage. It's more verbose, but it makes the cluster boundaries visible in the code rather than hiding them behind associations in Rails syntax.
Editor's note: This post was originally published in January 2023 and has been updated for accuracy.

Written by
Julie KentJulie is an engineer at Stitch Fix. In her free time, she likes reading, cooking, and walking her dog.